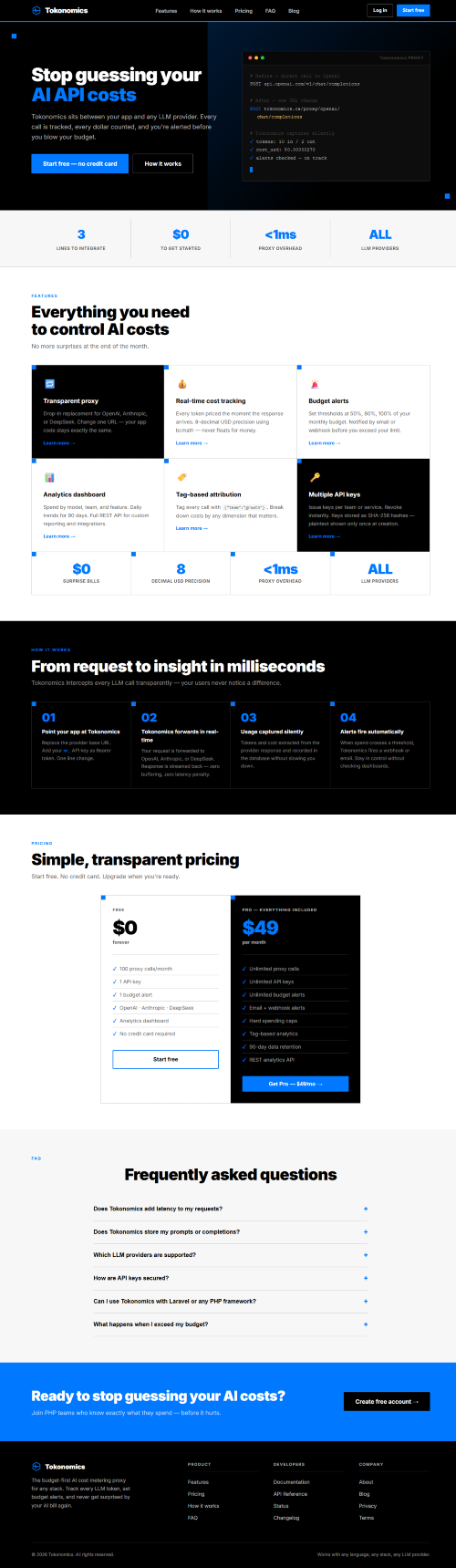
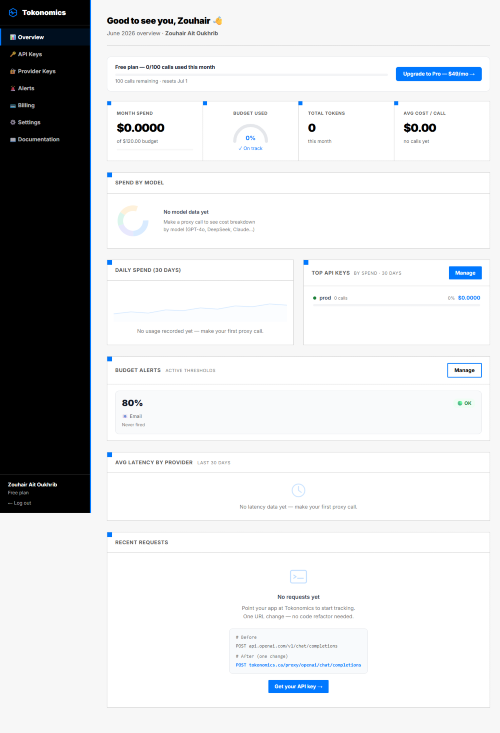
Tokonomics solves the problem of unpredictable AI API costs by providing a transparent proxy for LLM calls. This allows developers and businesses to monitor usage in real-time, ensuring that they can stay within budget without the fear of unexpected charges at the end of the month. With Tokonomics, every token call is accurately tracked, and users are alerted when costs approach set thresholds, making budget management seamless. Key features include real-time cost tracking with an 8-decimal precision, alerts via Slack, Microsoft Teams, email, or webhooks, and an analytics dashboard to review spending by model, team, and feature. Unlike alternatives that may lack real-time tracking or custom alerting, Tokonomics provides a comprehensive interface that works with multiple API keys and offers tag-based attribution for detailed cost analysis. With two pricing models, users can start for free with limited proxy calls, or choose the Pro plan at $49 per month for unlimited usage and enhanced features. FAQs: 1. Does Tokonomics add latency to my requests? No, it adds less than 1ms of overhead. 2. Does Tokonomics store my prompts or completions? No, it only records token counts and costs. 3. Which LLM providers are supported? OpenAI, Anthropic, and DeepSeek. Others are planned. 4. How are API keys secured? They are stored as SHA-256 hashes and never exposed. 5. Can I use Tokonomics with any programming language? Yes, it’s a standard HTTP proxy compatible with any HTTP client.
Published At