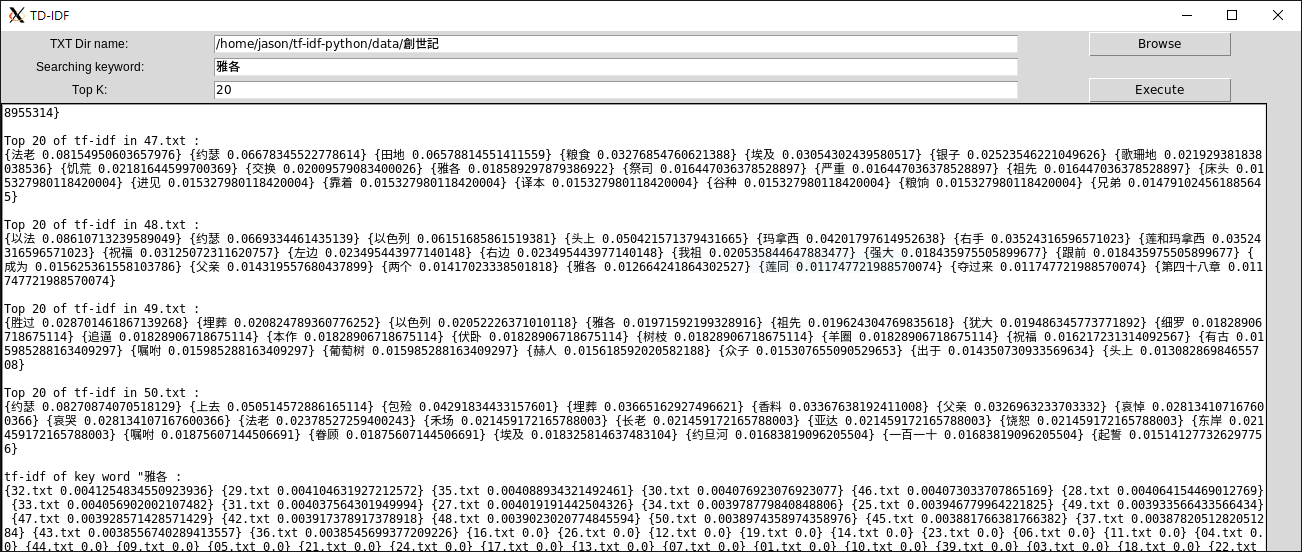
tf-idf, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. The purpose of this project is to implement tf-idf, input given a set of files with a specific relationship, and output the tf-idf weight value of each file. Specifically, the "word" with the highest k is displayed and its weight value, as shown in the figure above. Alternatively, you can enter a word and output a weight value for that word in all files. English can be segmented by blanks, but Chinese cannot. So we used Jieba Chinese text segmentation to collect the corpus of word. The word weighting value is then obtained using the tf-idf algorithm.
Tf-idf implemented in python
Term frequency–inverse document frequency(tf-idf) for Chinese novel/documents implemented in python



Published At