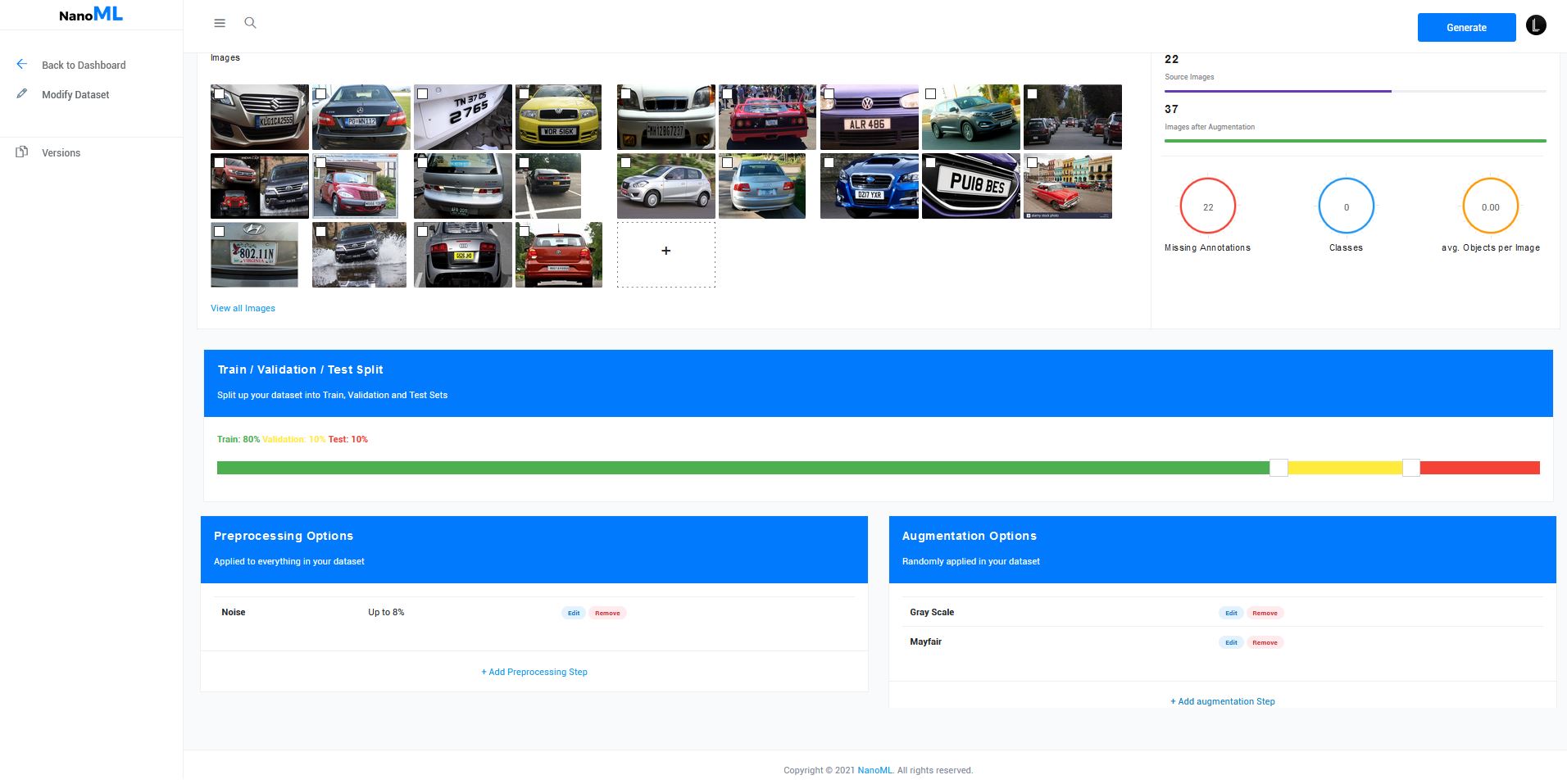
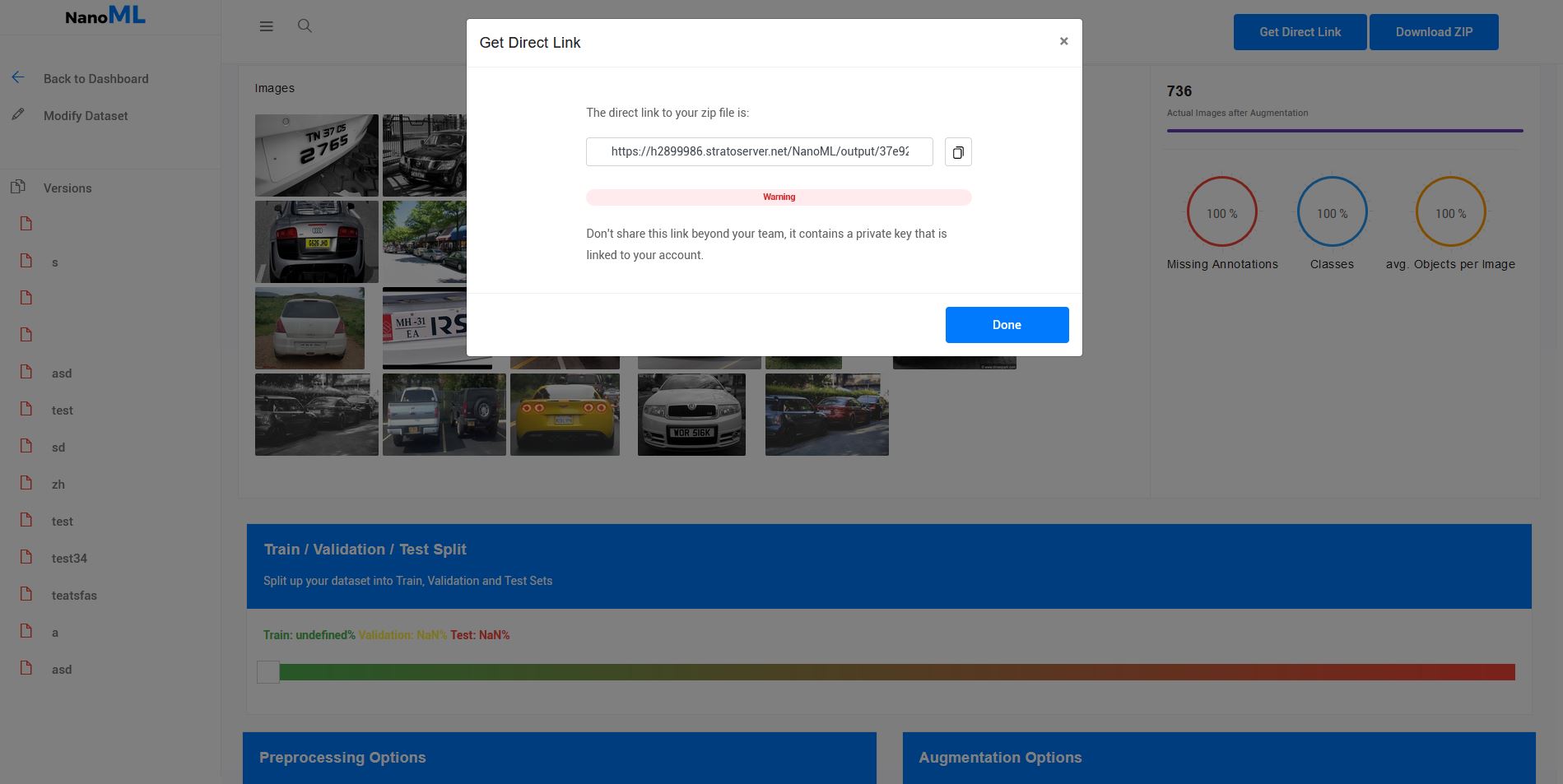
Hello there, I'm excited to introduce you to NanoML.org, a project I've been working on for the past few months in order to address some of the issues I've encountered while developing AI models. This tool aims to address three major issues: 1. The struggle with annotation formats and image processing for an infinite number of frameworks Looking around at other data scientists, I realized that this was a problem that many others were having as well. And it appears that everyone has a folder called "random python scripts" that contains one-time utilities for these common tasks. Furthermore, they also make general-purpose tools, such as Google Drive, perform tasks for which they were not designed for. 2. Bias in machine learning Currently, a lot of datasets used in industry and academia are extremely biased, and sadly, we are now also seeing the consequences of those poorly constructed inputs. As they say, garbage-in, garbage-out. Augmentation like i'll talk about in the 3. Point can help with this 3. Better Accuracy with less Work Most of the time, collecting data is a lot of work, it's expensive and then not even complete and therefore not accurate in all situations. Artificial Data (or Synthetic Data) can help with this. Instead of having to collect new Data to cover more edge cases you can just augment your current Data automatically I want to build the infrastructure to address these issues and lower the barrier to creating computer vision projects for everyone. You shouldn't have to reinvent the wheel to deploy computer vision products, just as you don't have to code your own database and web server to launch a website. I'm eager to hear what else you'd like me to add. I've already released a Beta Version that includes a limited dataset health check, several augmentation options, and direct downloads to your Jupyter notebooks, Google Colab, or whatever.
NanoML
Preprocess and augment datasets to improve accuracy, reduce bias, and even save time and money.