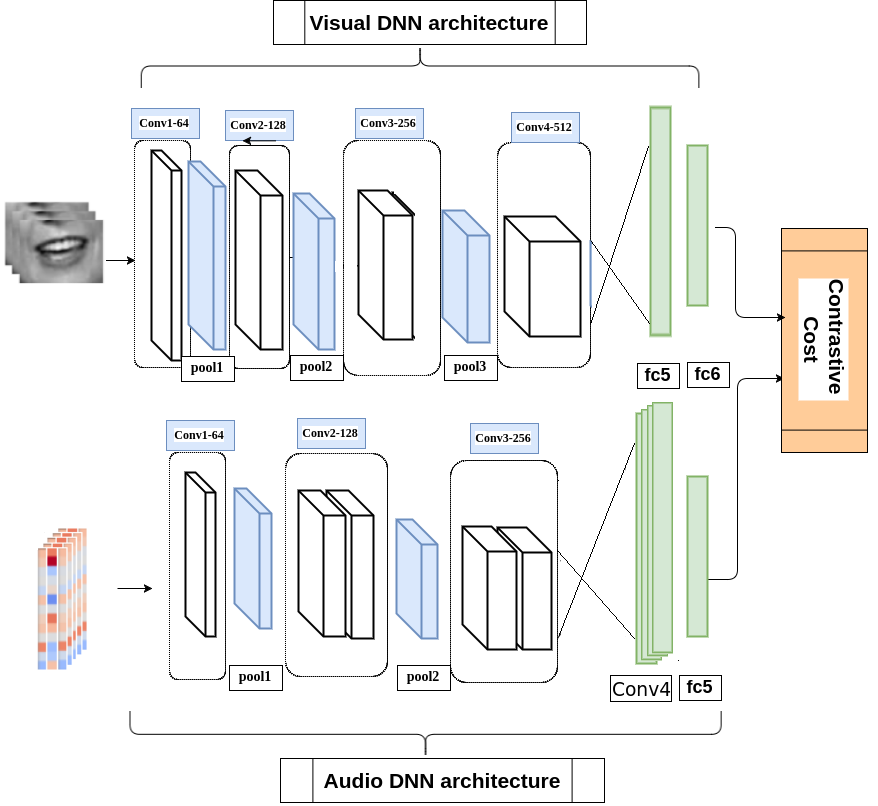
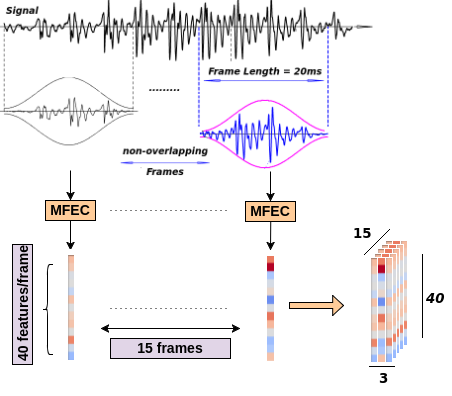
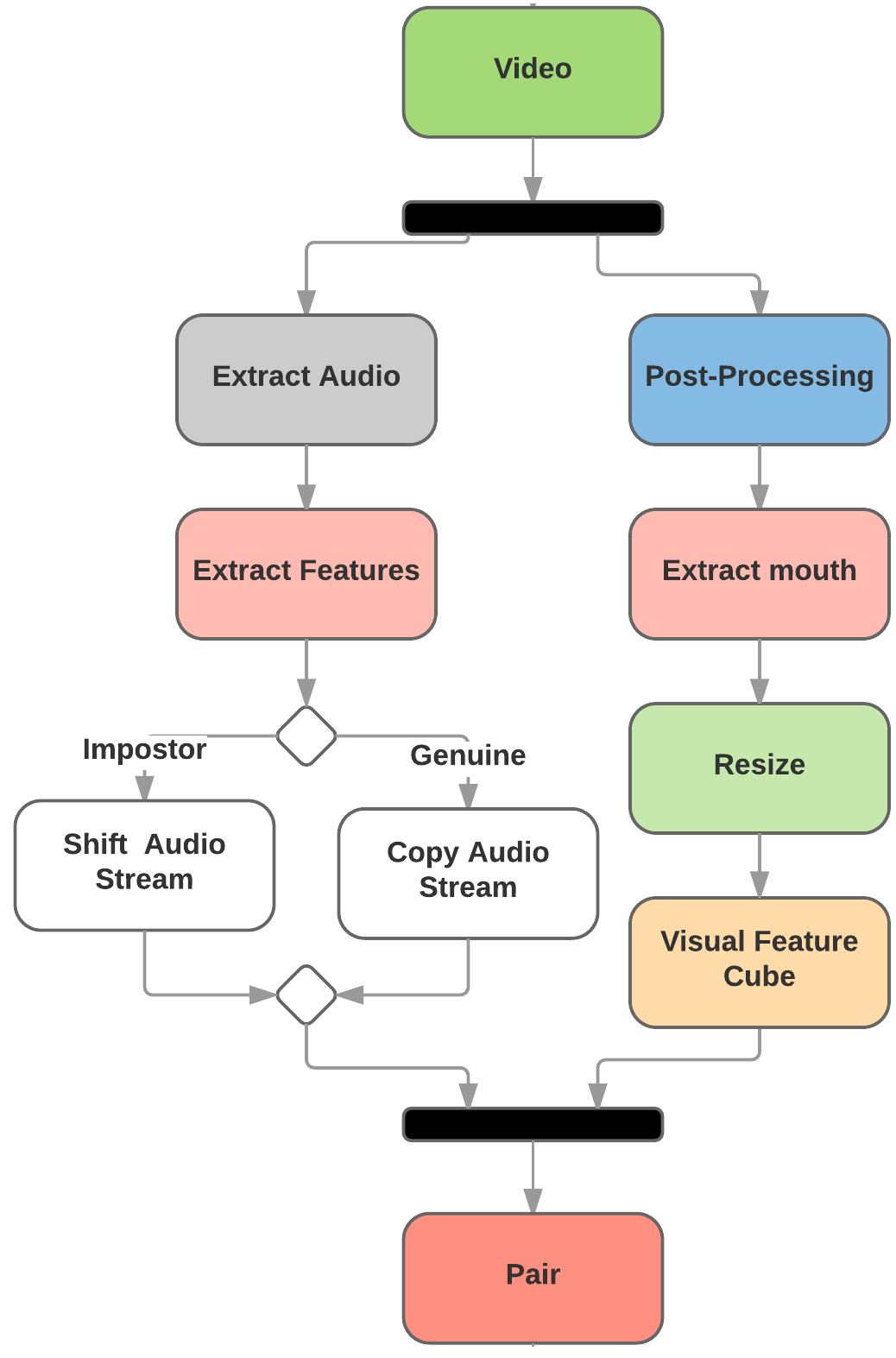
This code is aimed to provide the implementation for Coupled 3D Convolutional Neural Networks for audio-visual matching. Lip-reading can be a specific application for this work. The essential problem is to find the correspondence between the audio and visual streams, which is the goal of this work. We proposed the utilization of a coupled 3D Convolutional Neural Network (CNN) architecture that can map both modalities into a representation space to evaluate the correspondence of audio-visual streams using the learned multimodal features. The proposed architecture will incorporate both spatial and temporal information jointly to effectively find the correlation between temporal information for different modalities. By using a relatively small network architecture and much smaller dataset, our proposed method surpasses the performance of the existing similar methods for audio-visual matching which use CNNs for feature representation.
Cross Audio-Visual Recognition
This code provides the implementation for Coupled 3D CNNs for audio-visual matching