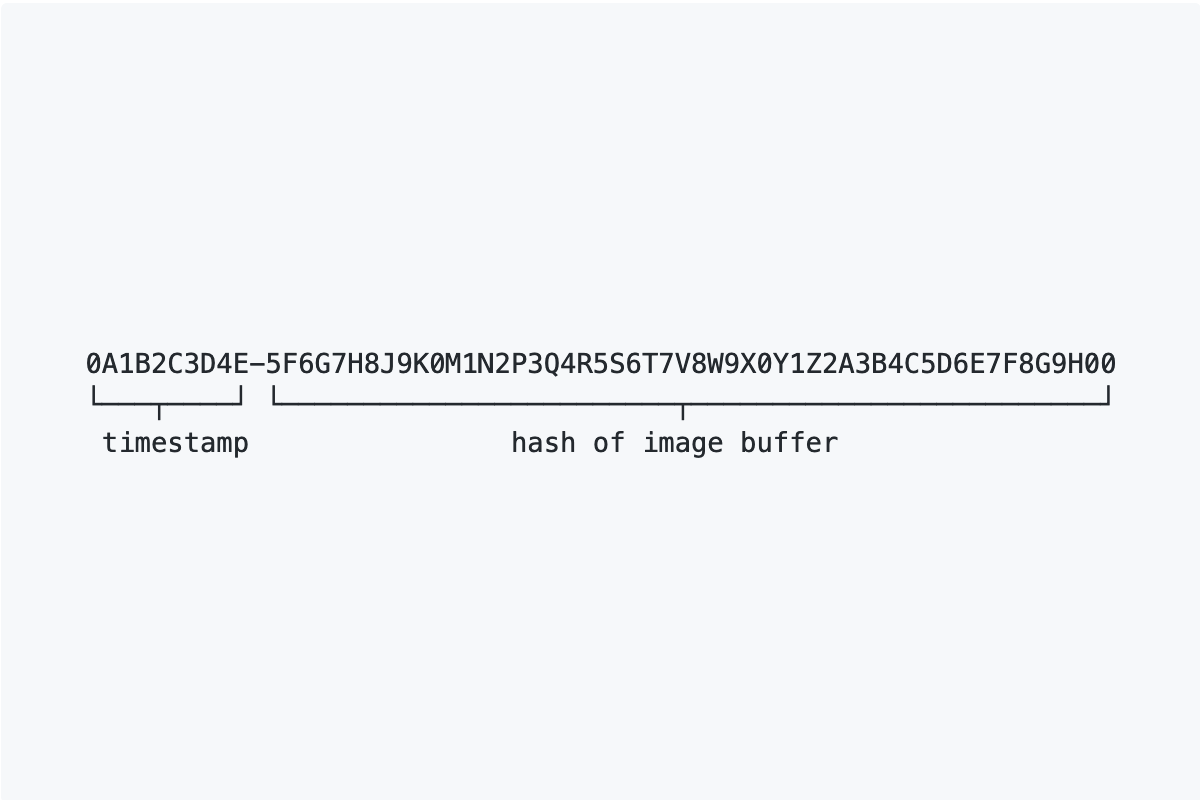
Usually, digital cameras and phones assign file names to images with a sequence of only 4 digits (e.g. IMG_1234.dng). Those names will easily clash for any sufficiently large amount of images. ciid tackles this problem by deriving a hash from the image buffer. Additionally to being able to derive an identifier that is very unlikely to clash, this hash can later be used to check the integrity of the image content. Some image processing programs update metadata of files (e.g inline JPEG- previews, tags, modified date). The resulting ciid will be unaffected from those changes, since only the actual image buffer is hashed. This has the nice side-effect that proprietary camera RAW file formats and converted .dng files will yield the same identifier most of the time.
Chronological Image Identifier
Uniquely identify image files while keeping the ability to sort them chronologically by name
Published At